Arsitektur Pengambilan Data Web Rust untuk Ekstraksi Data yang Dapat Diskalakan

Emma Foster
Machine Learning Engineer
TL;DR
- Pengambilan data web Rust paling efektif ketika pengambilan, pemrosesan, rendering, dan penyimpanan dipisahkan menjadi lapisan yang berbeda.
reqwestdanscrapermenangani banyak target statis dengan biaya sumber daya yang lebih rendah dan pemeliharaan yang lebih bersih.- Pengambilan data asinkron dengan Tokio meningkatkan throughput untuk beban kerja yang bergantung pada I/O, tetapi tetap memerlukan pembatasan laju, ulangan, dan kontrol antrian.
- Pengambilan data dengan browser tanpa antarmuka (headless browser) sebaiknya digunakan sebagai cadangan terpilih untuk halaman yang dirender JavaScript, bukan sebagai jalur default.
- Perlindungan bot, rotasi proxy, dan peristiwa CAPTCHA harus ditangani dengan kebijakan yang jelas dan desain otomatisasi yang kompatibel.
- Untuk alur otomatisasi yang sah yang memenuhi kebutuhan bisnis nyata, CapSolver dapat masuk ke lapisan cadangan yang sempit dengan mengikuti alur API resminya.
Pengambilan data web Rust paling efektif ketika dirancang sebagai arsitektur, bukan sebagai skrip tunggal. Artikel ini ditujukan untuk insinyur, tim data, dan operator teknis yang membutuhkan ekstraksi yang andal dalam skala besar. Kesimpulan utama datang terlebih dahulu: sistem pengambilan data web Rust yang terbaik menjaga jalur cepat sederhana dengan reqwest dan scraper, lalu menambahkan pengambilan data asinkron, pengambilan data dengan browser tanpa antarmuka, rotasi proxy, dan penanganan tantangan hanya ketika target benar-benar membutuhkannya. Struktur ini mengurangi biaya, meningkatkan stabilitas, dan membuat pipeline yang berjalan lama lebih mudah diobservasi.
Gambaran Umum Pengambilan Data Web Rust
Pengambilan data web Rust adalah pilihan kuat untuk pekerjaan ekstraksi besar karena menggabungkan keamanan memori dengan kinerja yang prediktif. Kualitas ini penting ketika seorang pekerja mungkin memproses ribuan halaman, menganalisis markup yang tidak stabil, dan menulis catatan yang dinormalisasi selama berjam-jam.
Artikel-artikel di hasil pencarian teratas menjelaskan cara mengambil satu halaman dan mem-parsing selektor. Materi ini berguna, tetapi jarang menjawab pertanyaan yang lebih sulit. Seperti apa tampilan arsitektur pengambilan data web Rust yang lengkap ketika Anda membutuhkan ketahanan, observabilitas, dan ruang untuk berkembang?
Desain produksi biasanya memerlukan lapisan pengambilan HTTP, lapisan pemrosesan, cabang rendering untuk halaman JavaScript, lapisan penyimpanan, dan lapisan operasional untuk ulangan, metrik, dan pengaturan kecepatan permintaan. Urutan yang benar juga penting. Mulai dengan jalur termurah terlebih dahulu. Ambil HTML mentah. Hanya parsing bidang yang Anda butuhkan. Naik ke pengambilan data dengan browser tanpa antarmuka hanya ketika HTML server tidak mengandung data target. Tambahkan rotasi proxy hanya ketika distribusi lalu lintas atau akses regional diperlukan. Tambahkan penanganan CAPTCHA hanya ketika alur otomatisasi yang kompatibel memiliki alasan yang valid untuk terus berjalan.
Untuk tim yang merencanakan batasan ini, pencarian web dan pengambilan data web membantu menjelaskan cakupan, dan cara mengekstrak data terstruktur adalah bacaan internal yang berguna sebelum pemetaan bidang dimulai.
Perpustakaan Inti untuk Pengambilan Data Rust
Pengambilan data web Rust biasanya dimulai dengan tiga blok bangunan: reqwest, scraper, dan Tokio. Dokumen resmi reqwest documentation menggambarkan reqwest sebagai klien HTTP tingkat tinggi dengan dukungan asinkron, cookie, redirect, TLS, dan dukungan proxy. Ini membuatnya menjadi lapisan transportasi yang praktis untuk pengambilan data web Rust.
Dokumen resmi Tokio async tutorial menjelaskan mengapa future dan model executor cocok untuk beban kerja I/O berkonkurensi tinggi. Hal ini penting karena pengambilan data web Rust menghabiskan sebagian besar waktunya menunggu server jarak jauh, bukan memakai CPU untuk perhitungan lokal.
Permintaan HTTP dengan reqwest
reqwest seharusnya berada di lapisan transportasi. Reuse klien tunggal per pekerja atau kelompok pekerja. Hal ini menjaga efektivitas pooling koneksi dan memberi Anda satu tempat untuk menentukan header, timeout, cookie, dan kebijakan proxy.
rust
use reqwest::Client;
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let client = Client::builder()
.user_agent("Mozilla/5.0")
.build()?;
let html = client
.get("https://example.com")
.send()
.await?
.error_for_status()?
.text()
.await?;
let document = Html::parse_document(&html);
let card = Selector::parse("article")?;
for node in document.select(&card) {
println!("{}", node.text().collect::<Vec<_>>().join(" "));
}
Ok(())
}Pola ini menjaga efisiensi pengambilan data web Rust pada halaman statis. Hal ini juga membuat penanganan kesalahan lebih mudah untuk distandarisasi. Pengecekan status, anggaran ulangan, dan log terstruktur dapat semua berada di sekitar lapisan permintaan alih-alih dicampur ke dalam kode parser.
Pemrosesan HTML dengan scraper
scraper seharusnya berada di lapisan parser yang tetap kecil dan dapat diuji. Jangan mencampur selektor dengan logika jaringan jika Anda mengharapkan template berubah. Parser yang kuat menerima HTML mentah dan mengembalikan catatan yang diberi tipe, catatan parsial, atau kesalahan ekstraksi yang jelas.
Pemisahan ini penting karena perubahan selektor adalah hal yang umum. Kelas berubah. Teks berpindah ke atribut. Node dekoratif muncul di antara elemen target. Dalam pengambilan data web Rust, isolasi parser membuat perubahan ini terlihat dalam pengujian sebelum seluruh pipeline mulai menulis data yang tidak lengkap.
Arsitektur Pengambilan Data Asinkron
Arsitektur pengambilan data asinkron adalah salah satu alasan utama mengapa pengambilan data web Rust dapat berskala baik di infrastruktur yang sederhana. Runtime tidak membuat situs web merespons lebih cepat. Ia membuat pekerja lebih efisien saat banyak permintaan menunggu respons jaringan atau asal.
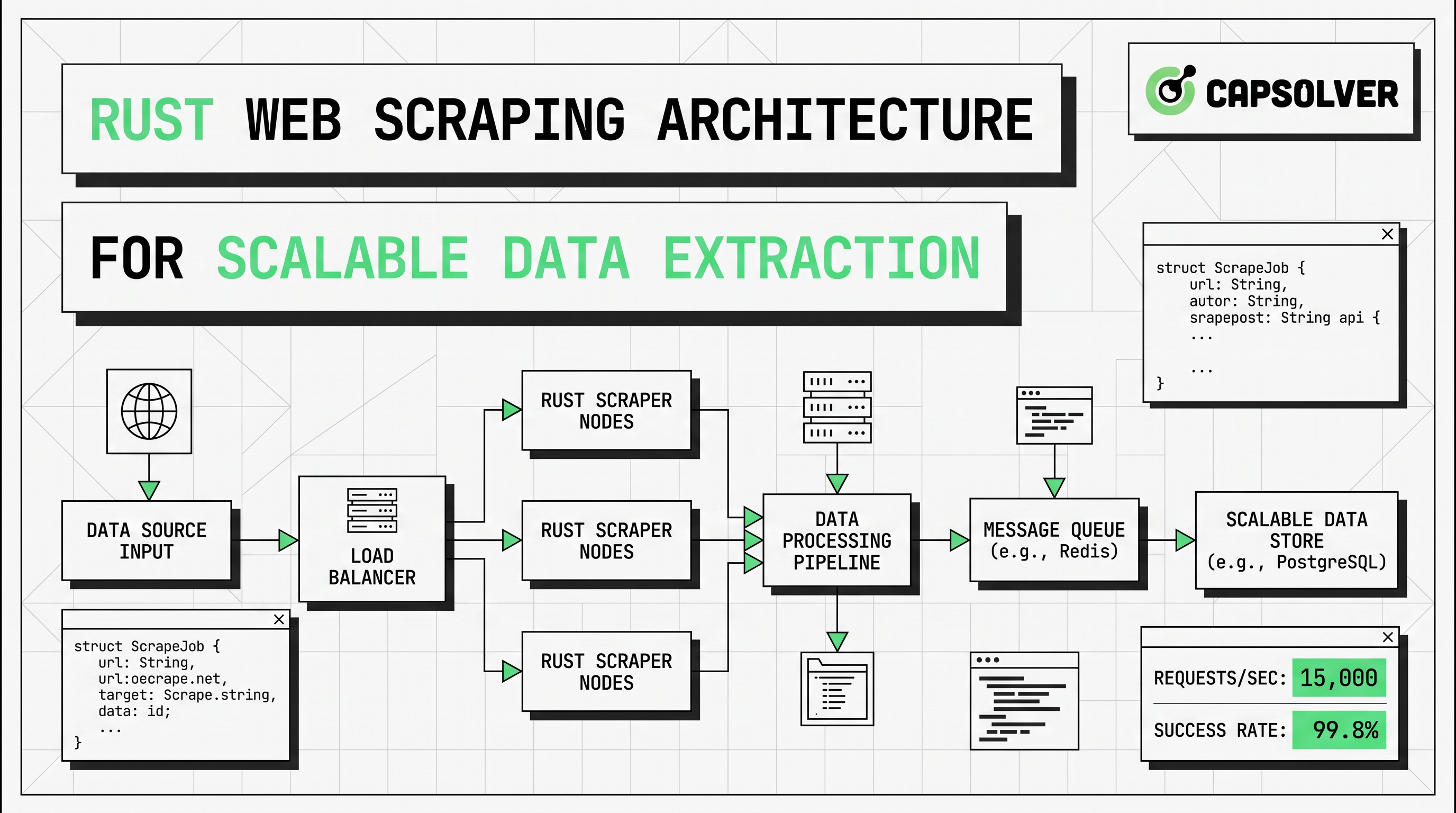
Pipeline pengambilan data web Rust yang berskala biasanya mengikuti struktur di bawah ini.
| Lapisan | Peran | Default Rust | Risiko utama |
|---|---|---|---|
| Penjadwal | Memilih URL dan prioritas | antrian atau saluran | lalu lintas mendadak |
| Pengambil | Mengirim permintaan HTTP | reqwest::Client |
403, 429, timeout |
| Parser | Mengekstrak bidang | selektor scraper |
perubahan template |
| Renderer | Memuat halaman JavaScript | pengambilan data dengan browser tanpa antarmuka | biaya CPU dan memori |
| Lapisan tantangan | Menangani peristiwa CAPTCHA yang diizinkan | cadangan CapSolver | tugas yang salah jenis |
| Penyimpanan | Menyimpan output yang dinormalisasi | JSON, CSV, DB | ketidakcocokan skema |
| Observabilitas | Melacak kesehatan dan kualitas | log, pelacakan, metrik | kehilangan data diam-diam |
Aturan desain utama adalah eskalasi yang selektif. Mulai setiap target pada jalur biaya rendah. Jika HTML yang dikembalikan sudah berisi data, tetap gunakan reqwest dan scraper. Jika bidang target hanya muncul setelah hidrasi, rendering sisi klien, atau peristiwa browser, arahkan hanya jenis halaman tersebut ke pengambilan data dengan browser tanpa antarmuka. Jika kontrol bot atau pemeriksaan CAPTCHA muncul di dalam alur yang disetujui, arahkan hanya peristiwa tersebut ke cabang cadangan yang sempit.
Ini adalah tempat di mana banyak sistem menjadi boros. Tim beralih ke otomatisasi browser untuk setiap permintaan. Hal ini meningkatkan biaya, mengurangi konkurensi, dan membuat kegagalan lebih sulit diklasifikasikan. Laporan State of JavaScript HTTP Archive menunjukkan bahwa halaman modern tetap sangat bergantung pada JavaScript, dengan ukuran transfer JavaScript rata-rata desktop 803,3 KB dan 23 permintaan skrip eksternal dalam tampilan laporan yang dipilih. Hal ini menjelaskan mengapa beberapa target membutuhkan rendering, tetapi tidak menjustifikasi penggunaan browser untuk setiap halaman.
Menangani Halaman yang Dirender JavaScript
Pengambilan data dengan browser tanpa antarmuka diperlukan ketika data dibuat setelah respons HTML awal. Tanda umum termasuk HTML server kosong, konten yang disisipkan setelah hidrasi, daftar scroll tak terbatas, atau halaman yang menampilkan bidang hanya setelah interaksi pengguna.
Pengambilan data web Rust seharusnya memperlakukan rendering browser sebagai cabang terpisah, bukan sebagai dasar universal. Gunakan untuk grid produk yang diisi setelah permintaan klien, dashboard yang dirender di browser, atau antarmuka di mana konten kunci disembunyikan di balik logika klik dan scroll. Pertahankan kumpulan browser kecil, dan isolasikan dari pekerja HTTP asinkron utama.
Aturan keputusan praktis sederhana. Jika data hadir dalam HTML mentah, tetap gunakan reqwest dan scraper. Jika bidang muncul hanya setelah eksekusi JavaScript, pindahkan jalur tersebut ke pengambilan data dengan browser tanpa antarmuka. Jika target yang sama juga menerapkan kontrol perlindungan bot, maka tinjau kebijakan jaringan, perilaku browser, dan kebutuhan cadangan bersamaan, bukan satu per satu.
Untuk bacaan internal terkait, otomatisasi browser untuk pengembang dan otomatisasi penyelesaian CAPTCHA di browser tanpa antarmuka sesuai dengan model berlapis ini.
CAPTCHA dan Batasan Pengambilan Data
Pengambilan data web Rust selalu memiliki batasan. Beberapa bersifat teknis. Lainnya bersifat hukum atau operasional. Sisi teknis mencakup reputasi IP, penanganan sesi, pemeriksaan fingerprint browser, API tersembunyi, dan perlindungan bot berlapis. Sisi operasional mencakup pengaturan kecepatan permintaan, anggaran kesalahan, dan dampak lalu lintas pada situs target.
Itulah sebabnya kepatuhan harus dibangun ke dalam arsitektur. Panduan robots.txt Google Search Central menjelaskan bahwa robots.txt terutama digunakan untuk mengelola lalu lintas crawler dan menghindari beban berlebihan pada situs. Titik ini penting untuk pengambilan data web Rust karena sistem yang dirancang dengan baik tidak hanya mencoba mengekstrak data. Ia juga mencoba mengontrol beban, mengurangi permintaan yang tidak perlu, dan menjaga perilaku pengumpulan data yang wajar.
Ketika alur otomatisasi yang sah menghadapi langkah CAPTCHA, CapSolver relevan sebagai layanan cadangan yang fokus. Pendekatan yang paling aman adalah mengikuti dokumen resmi alih-alih menciptakan format permintaan khusus. Dokumen CapSolver createTask menunjukkan pola tubuh permintaan standar di bawah ini.
json
POST https://api.capsolver.com/createTask
Host: api.capsolver.com
Content-Type: application/json
{
"clientKey":"YOUR_API_KEY",
"appId": "APP_ID",
"task": {
"type":"ImageToTextTask",
"body":"BASE64 image"
}
}Alur resmi yang sama mengembalikan taskId untuk tugas asinkron, yang kemudian harus diperiksa melalui getTaskResult. Dalam sistem pengambilan data web Rust yang berskala, logika tantangan ini harus tetap di luar jalur standar pengambilan dan pemrosesan sehingga permintaan normal tetap cepat dan mudah dipantau.
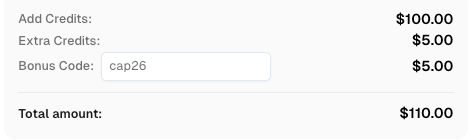
Klaim Kode Bonus CapSolver Anda
Tingkatkan anggaran otomatisasi Anda secara instan!
Gunakan kode bonus CAP26 saat menambahkan dana ke akun CapSolver Anda untuk mendapatkan tambahan 5% bonus pada setiap penambahan dana — tanpa batas.
Klaim sekarang di dashboard CapSolver Anda
Mengekspansi Pengambil Data Rust untuk Pengumpulan Data Skala Besar
Mengekspansi pengambil data Rust terutama tentang kontrol, bukan jumlah kode. Arsitektur harus mewajibkan konkurensi per domain, batas ulangan, anggaran timeout, dan validasi output. Tanpa kontrol ini, pekerja yang lebih cepat hanya menciptakan kegagalan yang lebih cepat.
Rotasi proxy seharusnya berada di lapisan transportasi, bukan di lapisan pemrosesan. Gunakan ketika permintaan perlu didistribusikan di sejumlah alamat IP untuk keseimbangan laju, akses regional, atau isolasi beban kerja. Pertahankan kebijakan spesifik. Putar berdasarkan domain, kelas akhir, atau jenis beban kerja. Hindari perubahan proxy acak yang menghancurkan kontinuitas sesi dan menambah kebisingan dalam debugging.
Ini juga adalah tempat sumber daya pendukung internal menjadi berguna. Layanan proxy terbaik dapat membantu mengevaluasi strategi jaringan, sementara hukum pengambilan data web adalah checkpoint internal yang berguna sebelum memperluas volume pengumpulan.
Sistem pengambilan data web Rust yang paling kuat juga mengukur kualitas ekstraksi secara langsung. Lacak tingkat keberhasilan, tingkat bidang kosong, pergeseran selektor, rasio rendering, latensi pengambilan median, dan biaya per catatan yang berhasil. Metrik ini menunjukkan kapan jalur HTML statis masih cukup dan kapan pengambilan data dengan browser tanpa antarmuka, rotasi proxy, atau penanganan tantangan menjadi terlalu mahal.
Ringkasan Perbandingan
| Pendekatan | Kasus penggunaan terbaik | Profil biaya | Profil keandalan | Catatan |
|---|---|---|---|---|
reqwest + scraper |
halaman statis atau sedikit dinamis | rendah | tinggi ketika selektor stabil | default terbaik untuk pengambilan data web Rust |
| Pengambilan data asinkron dengan pekerja Tokio | banyak URL yang bergantung pada I/O | rendah hingga menengah | tinggi dengan pembatasan laju | meningkatkan throughput, bukan kualitas parser |
| Pengambilan data dengan browser tanpa antarmuka | halaman yang dirender JavaScript | tinggi | menengah | isolasikan di kumpulan kecil |
| Rotasi proxy | kontrol laju terdistribusi dan akses geografis | menengah | menengah | berguna ketika identitas lalu lintas penting |
| Cadangan CapSolver | peristiwa CAPTCHA yang diizinkan dalam alur otomatisasi | berdasarkan peristiwa | menengah hingga tinggi | pertahankan implementasi yang sejalan dengan dokumen resmi |
Kesimpulan
Pengambilan data web Rust berskala ketika arsitektur tetap selektif. Gunakan reqwest dan scraper untuk jalur cepat. Tambahkan pengambilan data asinkron ketika Anda membutuhkan throughput lebih tinggi untuk pekerjaan yang bergantung pada I/O. Sisihkan pengambilan data dengan browser tanpa antarmuka untuk halaman yang benar-benar membutuhkan rendering. Pertahankan rotasi proxy dan penanganan tantangan sebagai lapisan cadangan yang terkendali. Desain ini menjaga biaya lebih rendah, meningkatkan observabilitas, dan membuat pemeliharaan parser jauh lebih mudah.
Jika pipeline saat ini mengarahkan setiap halaman melalui browser, peningkatan terbersih biasanya adalah pemisahan jalur. Pindahkan target statis kembali ke HTTP sederhana. Pertahankan halaman JavaScript di cabang rendering yang lebih kecil. Pertahankan logika tantangan terisolasi. Perubahan ini saja sering meningkatkan keandalan dan ekonomi unit.
FAQ
Apakah pengambilan data web Rust lebih baik daripada Python untuk pekerjaan besar?
Pengambilan data web Rust sering menjadi pilihan kuat ketika stabilitas jangka panjang, konkurensi, dan keamanan memori menjadi prioritas utama. Python masih memiliki ekosistem pengambilan data yang lebih luas, tetapi Rust menarik ketika efisiensi pekerja dan kinerja yang prediktif adalah prioritas utama.
Kapan saya harus beralih dari reqwest ke pengambilan data dengan browser tanpa antarmuka?
Beralih hanya ketika HTML server tidak mengandung bidang yang Anda butuhkan. Jika data target muncul setelah hidrasi, peristiwa sisi klien, atau permintaan API yang tertunda, pengambilan data dengan browser tanpa antarmuka menjadi dibenarkan.
Bagaimana pengambilan data asinkron membantu dalam Rust?
Pengambilan data asinkron membantu pengambilan data web Rust menangani banyak permintaan yang menunggu dengan sumber daya yang lebih sedikit. Ia meningkatkan throughput untuk beban kerja I/O, tetapi tetap memerlukan pembatasan laju, logika ulangan, dan pengujian parser.
Apakah saya selalu memerlukan rotasi proxy?
Tidak. Banyak pekerjaan bekerja dengan baik tanpa itu. Rotasi proxy penting ketika Anda membutuhkan akses regional, distribusi lalu lintas per-domain, atau mengurangi konsentrasi dari rentang IP tunggal.
Bagaimana saya harus menangani halaman CAPTCHA dalam alur kerja yang sesuai aturan?
Jaga penanganan CAPTCHA sempit, terdokumentasi, dan terpisah dari jalur pengambilan normal. Jika alur kerja otomasi yang sah membutuhkannya, gunakan alur tugas CapSolver resmi dan pastikan implementasinya konsisten dengan dokumentasi yang diterbitkan.
Lihat Lebih Banyak
web scrapingFeb 17, 2026
Cara menyelesaikan Captcha di Nanobot dengan CapSolver
Mengotomasi penyelesaian CAPTCHA dengan Nanobot dan CapSolver. Gunakan Playwright untuk menyelesaikan reCAPTCHA dan Cloudflare secara otomatis.

web scrapingFeb 10, 2026
Data sebagai Layanan (DaaS): Apa Itu dan Mengapa Penting pada 2026
Pahami Data sebagai Layanan (DaaS) pada 2026. Eksplor manfaatnya, kasus penggunaan, dan bagaimana DaaS mengubah bisnis dengan wawasan real-time dan skalabilitas.
